SQL
Archived Posts from this Category
Archived Posts from this Category
Posted by Chris Alcock on 22 Oct 2007 | Tagged as: Database, Development, SQL
A common database problem I have to explain to people is creating search functionality which allows a user to find a master record based on it having some or all of a specified set of related records. To illustrate this, consider a database which defines products, which can each have 0 or more features from a table of features assigned to them.
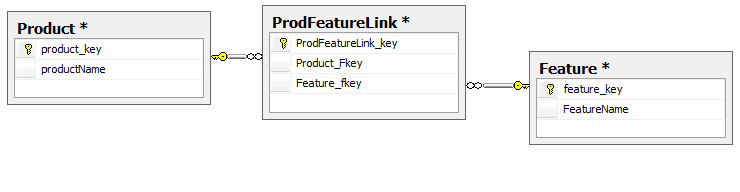
The table Product contains the details of the product (in our case, just a name – its an example after all). A list of features are supplied in the Feature table, and the relationship between a products and a feature is expressed by a record in the ProdFeatureLink table.
In this example, we will have 3 products, each with a different combination of the three features:
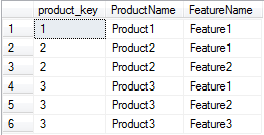
So, to summarise the data involved we can issue the following query:
select
p.product_key, P.ProductName, F.FeatureName from product p
inner join prodfeaturelink pfl on p.product_key = pfl.product_fkey
inner join Feature f on f.feature_key = pfl.feature_fkey
This gives the following results:
In our first case we are interested in products which have ‘Feature 1’. To find these we can use the previous query with a filter for the feature required:
select P.* fromproduct p
inner join ProdFeatureLink pfl on p.product_key = pfl.product_fkey
inner join feature f on f.feature_key = pfl.feature_fkeywhere
f.featureNAme = 'Feature1'
This gives the following result set:
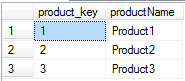
This query correctly returns Products 1,2 and 3.
In the next case, we are interested in products which have any or all of two features (Features 2 and 3). Again, this can be achieved by taking our original query and adding a where clause which filters for either of the features. This filter can be performed using ‘featureName IN (X,Y)‘ or by ‘FeatureName = X OR FeatureNAme = Y‘.
select distinct p.*from product p
inner join prodfeaturelink pfl
on pfl.product_fkey = p.product_key
inner join feature f
on f.feature_key = pfl.feature_fkeywhere
f.featureName in ('Feature2', 'Feature3')
And here is the result set:
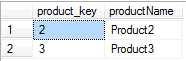
In order that we only get one mention of the product record the query above uses the Distinct clause, otherwise we would get duplication of results.
The final case is to find products that have both Features 2 and 3. This isn’t as simple as it might seem – we can’t just use the AND operator in place of the or, as each individual row of our original query’s results cannot contain two feature values. In order to do this, we need some new tools – specifically Group By, Having and an aggregate function or two.
Our previous query (Feature 2 AND/OR feature 3) provides the basis – we just need a way of finding only products which have both Feature 2 and 3. We can manage this by requiring that the count of the rows for each product is equal to the number of features we are searching for.
select p.product_key, p.productNamefrom product p
inner join ProdFeatureLink pfl on pfl.product_fkey = p.product_key
inner join feature f on f.feature_key = pfl.feature_fkeywhere featureName in ('Feature2', 'Feature3')group by p.Product_key, p.ProductNameHaving Count(product_key) = 2
giving the result set:
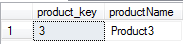
The placement of the criteria in this query is important. We must use the where to remove any data we are not interested in – so the WHERE filters our data down to only those products which have either feature 2 and 3. We then use the GROUP BY to gather up each product, and finally the HAVING checks that each product has the required number of features.
We can actually merge both the AND and the OR cases of this query together, as the only difference is that for an AND query we must have as many features against the product as we have specified, where as the OR query must have 1 or more.
declare @type char(3)Set @type='AND'--Set @type='OR'select p.product_key, p.productNamefrom product p
inner join ProdFeatureLink pfl on pfl.product_fkey = p.product_key
inner join feature f on f.feature_key = pfl.feature_fkeywhere featureName in ('Feature2', 'Feature3', ..., 'Feature n')group by p.Product_key, p.ProductNameHaving Count(product_key)>= CASE WHEN @type='AND' THEN n ELSE1 END
This query does rely slightly on the structure of the data involved. We rely on the fact that each product may only be assigned one instance of a feature- if a product may be assigned more than one instance of each feature then things do become a bit more difficult – but I’m going to save that for a later date.
UPDATE: Here is a SQL script of the examples used in the article:
AND/OR Searches of related records – SQL Script containing examples in the article
Posted by Chris Alcock on 28 Sep 2007 | Tagged as: .NET, Community, Database, Development, Links, SQL, Talks / Presentations

Last night I gave a presentation to the Liverpool Geekup group about NHibernate, thanks to everyone who came along – you were all a very nice audience. The slides from the presentation entitled Getting a Good Nights Sleep – ORM with NHibernate are available as a PDF, here. There are a number of links in the slides, but here is a more comprehensive list of links that people may find useful or interesting
Comments Off on Getting a good nights sleep – ORM with NHibernate
Posted by Chris Alcock on 11 Jul 2007 | Tagged as: Database, Development, SQL
There are a number of reasons that you might need to run the same (or similar) bits of SQL against a number of similar databases. I find myself doing this when I update some part of an application that runs against a number of individual client databases on the same server. In my case, the databases are consistently named in the format ‘client’ + ‘ApplicationName – i.e. ReflectivePerspectiveBLOG
sp_MSForEachDB is a built in SQL Server stored procedure which is undocumented in Books Online, but helps us out in this situation, allowing us to run a command on each database on the server
EXEC sp_MSForEachDB @command1 = '
use [?]
if (db_name() like '%BLOG')
BEGIN
--Perform our operation
update foo set bar = 1 where wibble=2
END
'
Another related stored proceedure is sp_MSForEachTable – this one allows you to do things to each table in the database:
EXEC sp_MSForEachTable @command1 = '
select top 10 * from ?
'
There are two ways of allocating values to variables in TSQL – SET and SELECT. Many people get into the habit of using SET to initialize their variables, like so
SET @foo = 1
SET @bar = 2
SET @wibble = 3
For performance purposes this is quite in-efficient as each use of SET is the equivaent of a SELECT statement.
SELECT, on the other hand has the advantage that it is able to set multiple variables at once:
SELECT @foo = 1, @bar = 2, @wibble=3
This single select statement is the equivalent of one of the SET statements above. The performance advantages of this increase when allocating values to variables from database tables:
SET @foo = (select foo from table where 1=1)
SET @bar = (select bar from table where 1=1)
does the same as the following statement, but only executes the query against the database once.
SELECT @foo = foo, @bar = bar from table where 1=1
Table variables are very useful and often forgotten about feature of SQL Server. You can use them much as you might a temporary table, however they have the added benefit that they will clean up after them selves, so you don’t have to remember to do the drop table #foo.
You can create Table Variables like so:
declare @tableVar table (col1 int, col2 int)
and from then on you can use them much as you would any other table
insert into @tableVar (col1, col2) values(1,2)
select * from @tableVar

The Morning Brew
is a daily .NET software development link blog published by Chris Alcock a software developer from the north west of England.
Check this box to have links open in new windows (This will set a cookie to save your preference)