SQL
Archived Posts from this Category
Archived Posts from this Category
Posted by Chris Alcock on 11 Jan 2007 | Tagged as: Database, Development, SQL
I quite often find myself using a subselect to get some metadata key value to use as part of a where clause. Some thing like the following:
select * from product where producttype_fkey=(select producttype_key from ProductType where TypeId='TEST')
I had been under the impression that the database engine would be clever enough to work out that the value the subselect returned was constant and that it would simply work in an equivalent way to this query:
declare @prodType int;
select @prodtype=producttype_key from ProductType where TypeId='TEST';
select * from product where producttype_fkey=@prodType
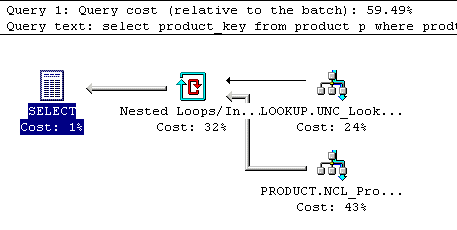
Infact this is not the case. The first query ends running as though the product table and the productType table were being inner joined together, giving an execution plan like this:
The second query (using the variable) has two parts to its execution, however the join is no longer there:
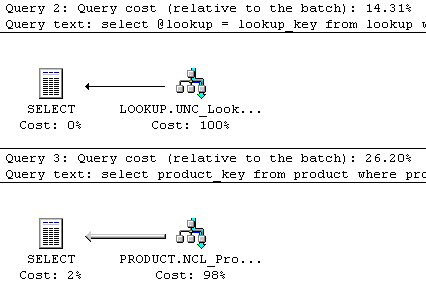
The significant thing about this is that when these two types of query are run together, the first query accounts for almost 60% of the execution, where as the two stage with variable version only accounts for a little over 40%, so it is significantly better to select the value out into a variable rather than subselecting (especially where the same value is required multiple times in a stored procedure.
Posted by Chris Alcock on 07 Jan 2007 | Tagged as: Database, Development, SQL
A post on the MSWebDev mailing list (archive only available to subscribers – but you should join, its a really useful list) asked ‘Does anyone think that set based is always possible and cursors need never be used?’.
I’m personally of the opinion that if cursors were never needed they wouldn’t be available to us, however there is a method I have used a number of times that works in more set based way, but still gives the ability to do per row processing. The main limitation is that the table(s)/views acting as the source must have a unique key. In the example below this key is a single field, but it should still be possible with composite key.
use tempdb
--Hide rows affected lines - they just clutter the messages window
Set NOCOUNT ON
--Create a table to store some data - this would be your complex table with many columns normally
create table Product (product_key bigint identity(1,1) not null, product_name nvarchar(200))
--Now fill the table with rather trival data
declare @count int
set @count = 0
while @count <1000
begin
insert into product (product_name) values ('Product' + cast (@count as nvarchar(5)))
set @count = @count +1
end
--uncomment below to see what that trivial data looks like
--select * from product
--This is the table that will act as our cursor
-- - using a table variable as performance is slightly better
-- as there is less logging than a temp table. Also the scopeing works well for us
declare @keybag table (theKey bigint)
--Grab the keys of all the records for the 'cursor' - obviously this can be filtered and ordered insert into @keybag select product_key from product --the key of the record we are currently working on declare @currentKey bigint --variable for us to fill in a similar way to a cursor declare @currentProduct nvarchar(200) --loop for all keys in the @keyBag (NB we will be removing keys as we use them while exists(select theKey from @keybag) begin --Get the next Key select top 1 @currentKey = theKey from @keybag -- and pull out the record from the real table using that key -- note that more than one column can be pulled into a variable here too! select @currentProduct = product_name from product where product_key = @currentKey --Do per row processing - we just print the name out - but you can do whatever you like! print @currentProduct --finally remove the key from the keybag as we have done it - forgetting this line will loop for ever :( delete from @keybag where theKey = @currentKey end --clean up the test table drop table product
I've done a little performance testing on this in the past to see how well it performs against cursors, but I don't have any numbers to hand - I'll have to check the Wiki at work to see if I put them there. I seem to revall that it was comparable or slightly faster in my tests, but I suspect your mileage will vary, but it can be a useful method.
Also worthy of note is c# Code Format the web based formatter I used to format the code above (even if it did mess up the comments when there are keywords in the line).
Update: Dropped the syntax highlighting when importing into this new blog
Comments Off on Cursing Cursors

The Morning Brew
is a daily .NET software development link blog published by Chris Alcock a software developer from the north west of England.
Check this box to have links open in new windows (This will set a cookie to save your preference)